Once the dataset is created, we can initiate the model training. In case model training is using AutoML, users do not need to worry about the algorithm selection. Follow below steps to start model training:
Step 1: Model training preparation
After checking the statistics of the data, users can click on done, as shown in the Figure 2.9 to navigate to training phase as shown in Figure 2.10:
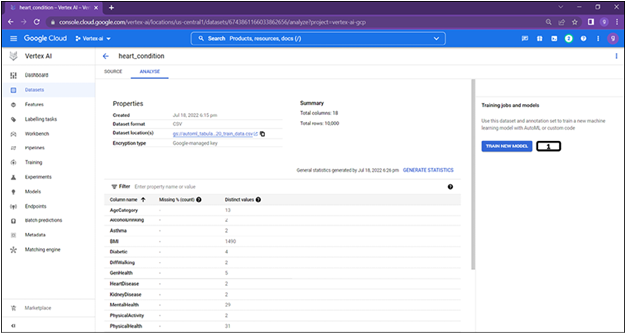
Figure 2.10: Tabular AutoML model training initiation
- Click on train new model.
Step 2: Training method selection.
First step in the model training is to choose the dataset and objective as shown in the Figure 2.11:
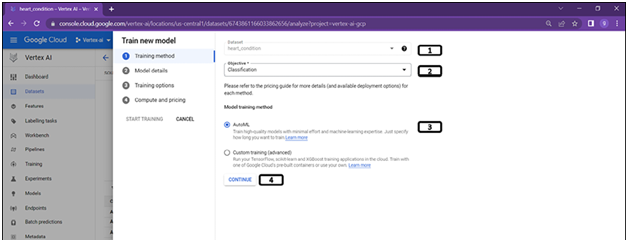
Figure 2.11: Training method selection
- Select the dataset created.
- Select the objective to be classification (since the target column is categorical).
- Select AutoML.
- Click Continue.
Step 3: Model details selection
Model details allows users choose between training new model or new version of the trained model as shown in Figure 2.12:
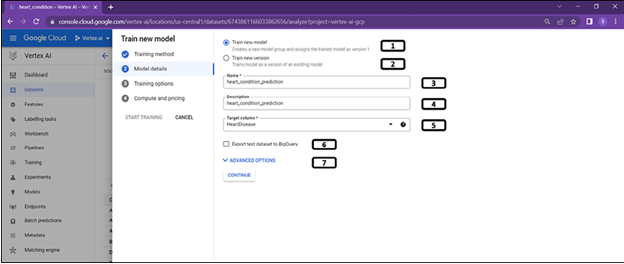
Figure 2.12: Model selection details
- Select Train new model.
- If a model is already trained and the users want to retrain the model due to change in the data, then this option lets them train model with new version.
- Provide Name to the model.
- Provide a Description to the model.
- Select the Target column.
- Test split of the dataset can be exported to BigQuery if the option is selected.
- Clicking on Advanced Options lets users choose the data split.
Step 4: Data split for the training
Clicking on advanced options will give more options on the data split as shown in Figure 2.13:
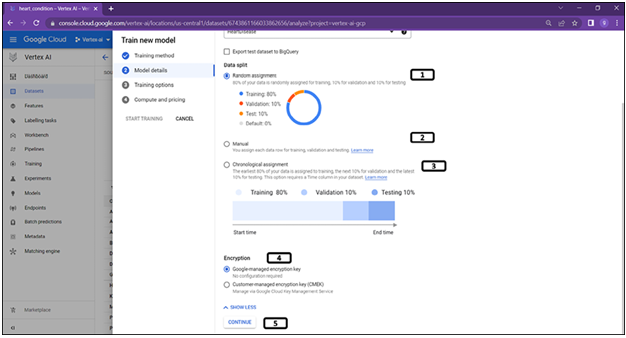
Figure 2.13: Model selection details (data splitting)
- 80% of the data is used for training and 10% for validation and test respectively. And this split happens at random.
- Users can also provide an additional column mentioning about the split for each record in the dataset.
- If Chronological assignment is chosen, first 80% of the data will be used for training, next 10% is used for validation and the last 10% of the data is used for test.
- Advanced options – For encryption.
- Click Continue.
Step 5: Training options
Transformation options are provided for users as shown in Figure 2.14:
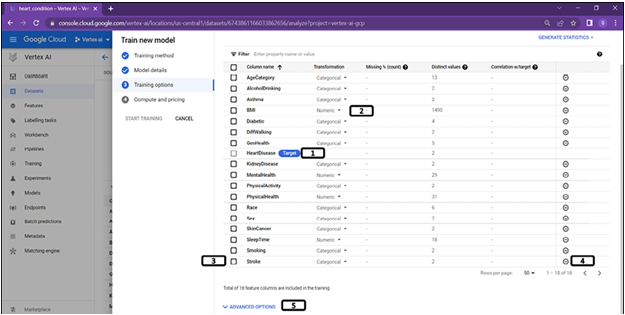
Figure 2.14: Training options (data transformation)
- Target column is assigned.
- AutoML does not always choose the right transformation to be applied. It is good to check manually and change the transformation type. Click on the arrow to change the transformation type.
- If any column needs to be excluded from training, column needs to be selected.
- Once the column is selected, click on “-”.
(In our use case, we are considering all the columns for training, and there is no need to follow steps 3 & 4).
5. Click Advanced options.
Step 6: Select optimization objectives
Users will be provided with additional training settings options as shown in Figure 2.15:
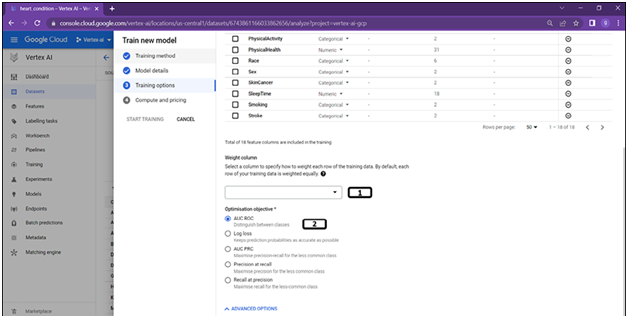
Figure 2.15: Training options (optimization objective)
- By default, AutoML considers all the columns to be equally important, however users are given an option to add more importance to the required columns.
- Users are given options to choose the optimization objectives based on the use cases.
- Click Continue.
Step 7: Compute and pricing
Final step for model training is as shown in the Figure 2.16:
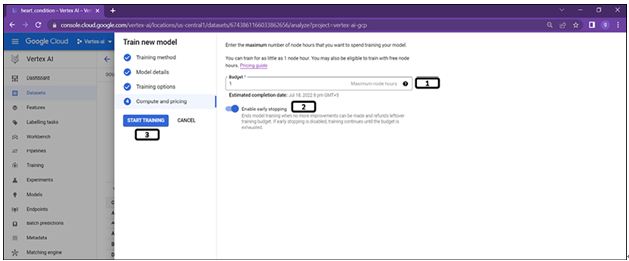
Figure 2.16: Training initiation
- Users can specify the maximum node hours for training, the minimum value for tabular dataset is 1. A node hour represents the time a virtual machine spends on training the model.
- Early stopping can be enabled to stop the training if model cannot be trained any further.
- Click on Start training.
Tabular data structure recommended for AutoML (classification and regression):
- Data must be 100 GB or smaller
- Number columns must be greater than 2 and not more than 1000
- Number rows must be greater than 1000 and less than 100000000