Once the virtual machine is created, it will be listed under VM instances as shown in Figure 1.39:
Figure 1.39: VM instance created and listed under VM instances
- Click on the instance type to see the details of the VM (including region, zone of VM, machine configuration, load monitoring for the CPU utilization, memory utilization, and so on).
- Internal IP address is the subnet IP address.
- External IP address to communicate with external devices
- SSH for connecting to the VM.
Step 1: Accessing the VM
Follow the steps described in Figure 1.40 and Figure 1.41 to access the created VM instance:
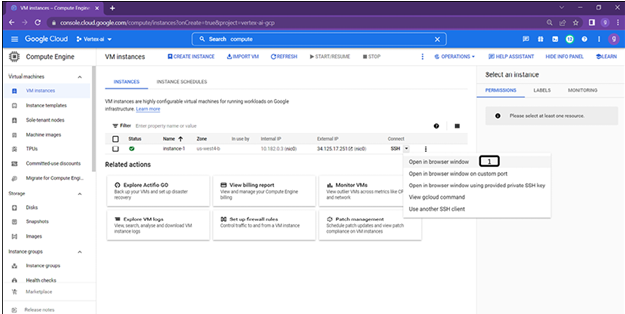
- Click on the SSH options and select open in browser window.
New window will open, SSH keys will be transferred and connection will be established as shown in Figure 1.41:
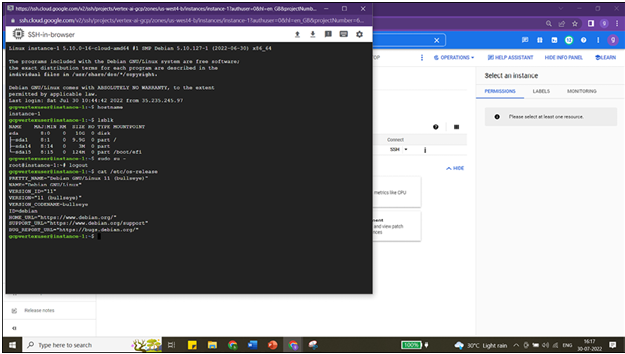
Try these commands in the window:
a. Hostname (to get the name of VM instance)
b. Lsblk (for the disk information)
c. Sudo su – (to check the root access)
d. Logout (to exit route access)
e. Cat /etc/os-release (to see the Operating system details)
f. Logout (to close the connection)
Follow the steps described in Figure 1.42 to delete the VM instance:
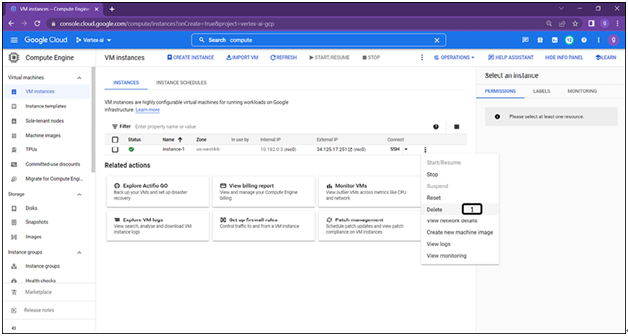
- Click on three dots and select Delete.
- The pop-up window will ask for the confirmation.
Note: All the compute resources are expensive in any platforms, make sure to decommission them after use.
Anyone has the power to analyze terabytes of data in the matter of seconds using BigQuery, which is a fully managed and serverless data warehouse solution offered in the Google Cloud Platform. This facilitates the management and analysis of data via the use of built-in capabilities such as machine learning, geospatial analysis, and business intelligence. The serverless architecture of BigQuery employs SQL queries to provide organizations with answers to their most pressing problems while requiring no administration of their underlying infrastructure.
The Google BigQuery architecture is built on Dremel, a distributed system designed by Google to query massive databases. The execution of the query is broken up into slots in Dremel, which enables fairness even when numerous users are concurrently searching the database. Under the hood, Dremel uses Jupiter, Google’s internal data center network, to access the data storage on the distributed file system that is nicknamed Colossus. Jupiter is also the backbone of Google Cloud Storage. Data replication, data recovery, and management of data dissemination are all handled by Colossus. BigQuery utilizes a columnar storage structure for its data, which results in a high compression ratio and a high scan throughput. On the other hand, you may also utilize BigQuery with data that is stored in other Google Cloud services, such as Bigtable, Cloud Storage, Cloud SQL, and Google Drive.
Because of its architecture that is specifically designed to handle large amounts of data, BigQuery performs at its peak when it is given several petabytes of information to evaluate. BigQuery is best suited for use cases in which people need to make interactive ad-hoc queries of read-only datasets. In most cases, complicated analytical queries to a relational database take several seconds to run. This is an ideal situation for using BigQuery, which is why it is often utilized towards the end of the Big Data ETL pipeline, on top of processed data. BigQuery performs very well in circumstances in which the data does not undergo frequent changes because it comes with its own cache.
There is no need to install, setup, or maintain any underlying infrastructure in order for it to function properly because it is a completely managed service. Customers are only paid for the amount of data they keep and the number of queries they run against the database.